

🌟前言
在人工智能语音生成领域,开源项目不断为我们带来惊喜。今天要介绍的 PilotTTS,就是一款能让 AI 学会 “说话” 的强大开源工具,为语音生成应用开拓了新的可能性。
📢软件介绍
PilotTTS 是一个让 AI 学会 “说话” 的语音生成开源项目,解压即可使用。它是基于大型语言模型的文本转语音(TTS)系统,构建了简化架构,采用完全开源组件,通过严谨数据工程实现竞争性能。
💫功能亮点
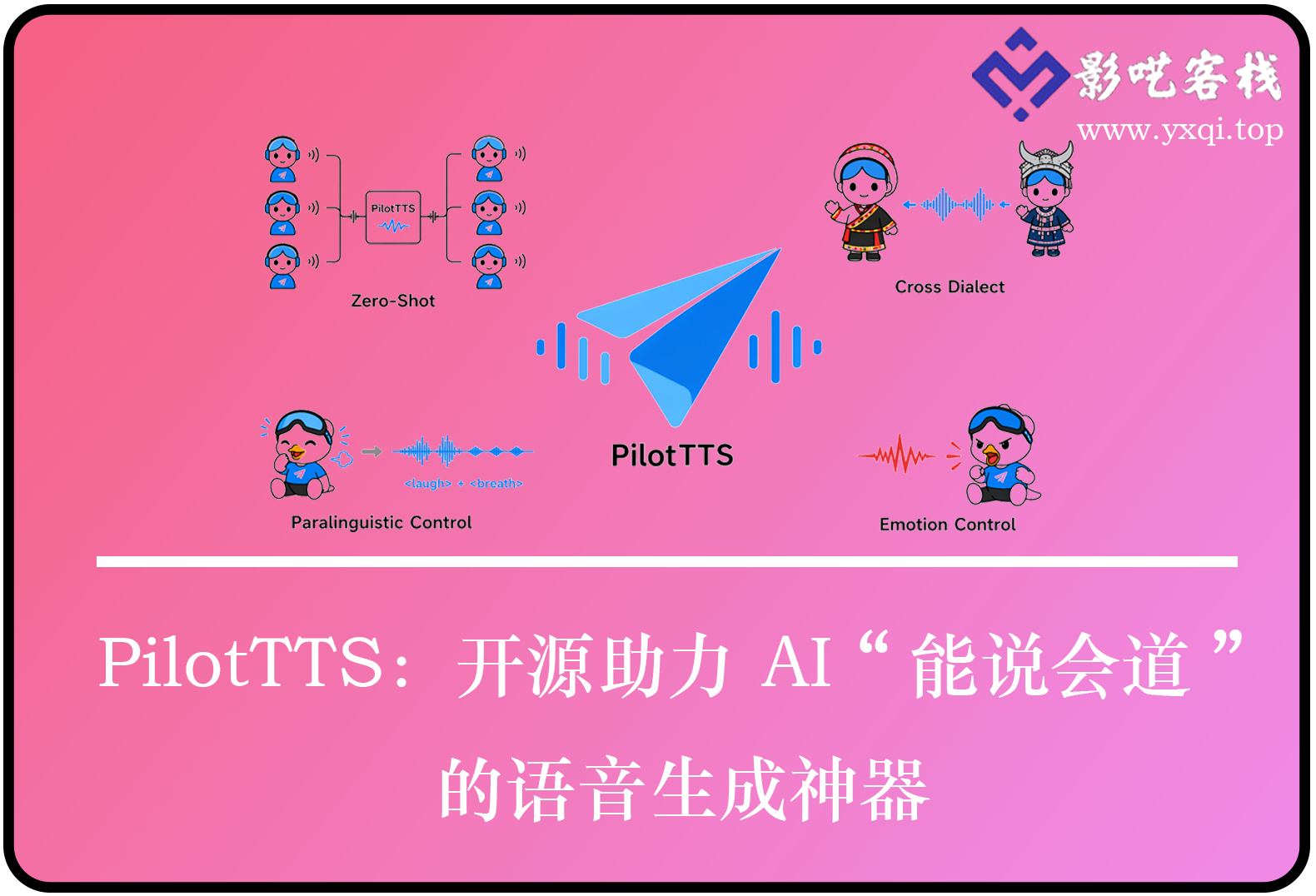
- 模仿任何人说话:仅需录制 5 – 15 秒音频,AI 就能学习并模仿该声音。
- 带有情感的朗读:支持 11 种情绪表达,如开心、悲伤等,让朗读更生动。
- 说方言:支持 14 种中国方言,像东北话、广东话等,满足多样化语言需求。
- 加入笑声和呼吸声:可使 AI 说话时自然融入笑声、呼吸等细节,声音更逼真。
其实际应用场景广泛,涵盖视频配音、有声书制作、导航播报、辅助视障人士等多个方面。
🧩图片展示
![图片[1]-PilotTTS:开源助力 AI “能说会道” 的语音生成神器](https://tuchuang.org.cn/imgs/2026/06/15/6ccf9a5471a767d9.jpg)
安装 ⚙️
克隆与安装
git clone https://github.com/xxx/pilot-tts.git
cd pilot-tts环境设置
conda create -n pilot-tts python=3.10 -y
conda activate pilot-tts
pip install -r requirements.txt模型下载
# ModelScope
from modelscope import snapshot_download
snapshot_download('AmapVoice/PilotTTS', local_dir='pretrained_models/')
# HuggingFace
from huggingface_hub import snapshot_download
snapshot_download('AmapVoice/PilotTTS', local_dir='pretrained_models/')1. Pilot-TTS模型(我们的权重)
这包括:、、和。pilot_tts.ptpilot_tts_instruct.pttokenizer/
2. 第三方开源模型
从它们各自的开源项目下载以下依赖:
```python
from huggingface_hub import snapshot_download
# w2v-bert-2.0 (audio feature extractor)
snapshot_download('facebook/w2v-bert-2.0', local_dir='pretrained_models/w2v-bert-2.0')
注:(来自MaskGCT)包含在Pilot-TTS模型包中。
wav2vec2bert_stats.pt
最终目录结构
pretrained_models/
├── pilot_tts.pt # Base model (zero-shot voice cloning)
├── pilot_tts_instruct.pt # Instruct model (emotion, paralanguage, dialect)
├── Qwen3-0.6B/ # LLM backbone (from Qwen)
├── w2v-bert-2.0/ # Audio feature extractor (from Meta)
├── wav2vec2bert_stats.pt # Feature normalization stats (from MaskGCT)
└── CosyVoice3-0.5B/ # Flow-matching vocoder (from FunAudioLLM)
快速入门 📖
用一个命令运行所有推理演示:
python demo.py推断
Python API
from demo import load_engine, synthesize
# Zero-shot voice cloning (base model)
engine = load_engine(
config_path="configs/infer_pilot_tts.yaml",
checkpoint="pretrained_models/pilot_tts.pt",
)
synthesize(engine, text="你好,世界!",
prompt_wav="assert/prompt.wav",
output_path="output/clone.wav")
# Load instruct model (emotion, paralanguage, dialect)
engine_instruct = load_engine(
config_path="configs/infer_pilot_tts_instruct.yaml",
checkpoint="pretrained_models/pilot_tts_instruct.pt",
)
# Emotion synthesis
synthesize(engine_instruct, text="今天天气真好啊!",
prompt_wav="assert/prompt.wav",
emotion="happy", output_path="output/happy.wav")
# Paralanguage
synthesize(engine_instruct, text="这太好笑了<|LAUGH|>停不下来",
prompt_wav="assert/prompt.wav",
output_path="output/laugh.wav")
# Dialect (Henan)
synthesize(engine_instruct, text="中不中啊,咱俩一块儿去吃胡辣汤吧",
prompt_wav="assert/prompt.wav",
language="zh-henan", output_path="output/henan.wav")命令行
# Zero-shot voice cloning (base model)
python inference.py \
--checkpoint pretrained_models/pilot_tts.pt \
--prompt-wav assert/prompt.wav \
--text "需要合成的目标文本" \
--output output/zeroshot.wav
# Emotion synthesis (instruct model)
python inference.py \
--config configs/infer_pilot_tts_instruct.yaml \
--checkpoint pretrained_models/pilot_tts_instruct.pt \
--prompt-wav assert/prompt.wav \
--text "今天天气真好啊,我们去公园玩吧!" \
--emotion happy \
--output output/emotion.wav
# Paralanguage (instruct model)
python inference.py \
--config configs/infer_pilot_tts_instruct.yaml \
--checkpoint pretrained_models/pilot_tts_instruct.pt \
--prompt-wav assert/prompt.wav \
--text "这个笑话太好笑了<|LAUGH|>我真的忍不住" \
--output output/paralang.wav
# Dialect synthesis (instruct model)
python inference.py \
--config configs/infer_pilot_tts_instruct.yaml \
--checkpoint pretrained_models/pilot_tts_instruct.pt \
--prompt-wav assert/prompt.wav \
--text "中不中啊,咱俩一块儿去吃胡辣汤吧" \
--language zh-henan \
--output output/dialect.wav支持的控制
| 特色 | 用途 | 模型 |
|---|---|---|
| 语音克隆 | 提供即时音频 | 两者兼具 |
| 情感 | --emotion <tag> | 教导 |
| 副语言 | 文本中插入标签 | 教导 |
| 方言 | --language <dialect> | 教导 |
情绪:
| 标签 | 情感 | 标签 | 情感 |
|---|---|---|---|
happy | 开心 | sad | 悲伤 |
angry | 愤怒 | surprise | 惊讶 |
fear | 恐惧 | disgust | 厌恶 |
serious | 严肃 | concern | 关切 |
blue | 忧郁 | disdain | 轻蔑 |
neutral | 中性/平静 | psychology | 心理活动 |
unknown | 不指定情感 |
副语言标签:
| 标签 | 描述 |
|---|---|
<|LAUGH|> | 笑声 |
<|BREATH|> | 呼吸声 |
<|COUGH|> | 咳嗽 |
<|CRY|> | 哭泣声 |
<|LAUGH_SPAN|>...<|/LAUGH_SPAN|> | 包裹笑声文本 |
方言:
| 标签 | 方言 | 标签 | 方言 |
|---|---|---|---|
zh-dongbei | 东北话 | zh-shandong | 山东话 |
zh-henan | 河南话 | zh-shan1xi | 山西话 |
zh-minnan | 闽南语 | zh-gansu | 甘肃话 |
zh-ningxia | 宁夏话 | zh-shanghai | 上海话 |
zh-chongqing | 重庆话 | zh-hubei | 湖北话 |
zh-hunan | 湖南话 | zh-jiangxi | 江西话 |
zh-guizhou | 贵州话 | zh-yunnan | 云南话 |
WebUI
推出基于Gradio的交互界面:
python webui.py --port 9000
©️开源项目地址:
https://github.com/AMAPVOICE/PilotTTS
网盘下载链接:
© 版权声明
THE END








![表情[qiang]-影呓客栈](https://www.yxqi.top/wp-content/themes/yykz/img/smilies/qiang.gif)


暂无评论内容